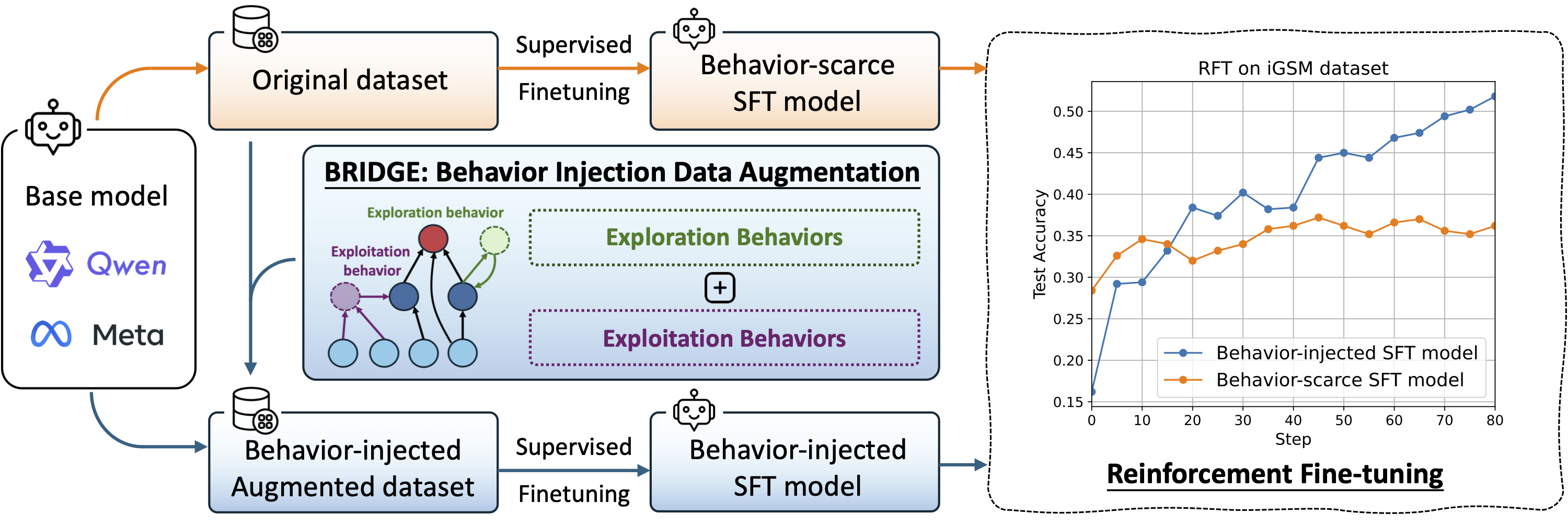
BRIDGE
BRIDGE
Large Language Models (LLMs) can respond very inconsistently to reinforcement finetuning: some show substantial performance gains, while others plateau or even degrade. We analyze the per-step influence of the RL objective and identify two key conditions for effective post-training: (1) RL-informative rollout accuracy, and (2) strong data co-influence, which quantifies how much the training data affects performance on other samples. We propose behavior injection, a task-agnostic data-augmentation scheme applied prior to RL. Behavior injection enriches the supervised finetuning (SFT) data by seeding exploratory and exploitative behaviors, effectively making the model more RL-ready.
The per-step influence of one query on the (GRPO) learning objective in RL finetuning can be formulated as: \[ \Delta \mathcal{J} = \mathbb{E}_{\mathbf{q}'\sim Q,\mathbf{o}'\sim\pi_\theta(\cdot|\mathbf{q}')} \left[\sqrt{\alpha(1-\alpha)} \cdot A(\mathbf{q}',\mathbf{o}') [\mathcal{K}_\theta^+ - \mathcal{K}_\theta^-]\right] \]
There are two key factors:
(1) rollout accuracy distribution: a query with rollout accuracy $\alpha$ contributes to the per-step influence with coefficient $\sqrt{\alpha(1-\alpha)}$.
(2) the data co-influence coefficient $\mathcal{K}_\theta$, which indicates how LLM acquires knowledge from both successful and failed rollout experiences.
We focus on the characteristics of the base model in terms of exploration and exploitation, which fundamentally influence both the accuracy distribution and the co-influence structure. Therefore, we propose Behavior injection data augmentation (BRIDGE) that seeds exploratory and exploitative behaviors into the SFT data.
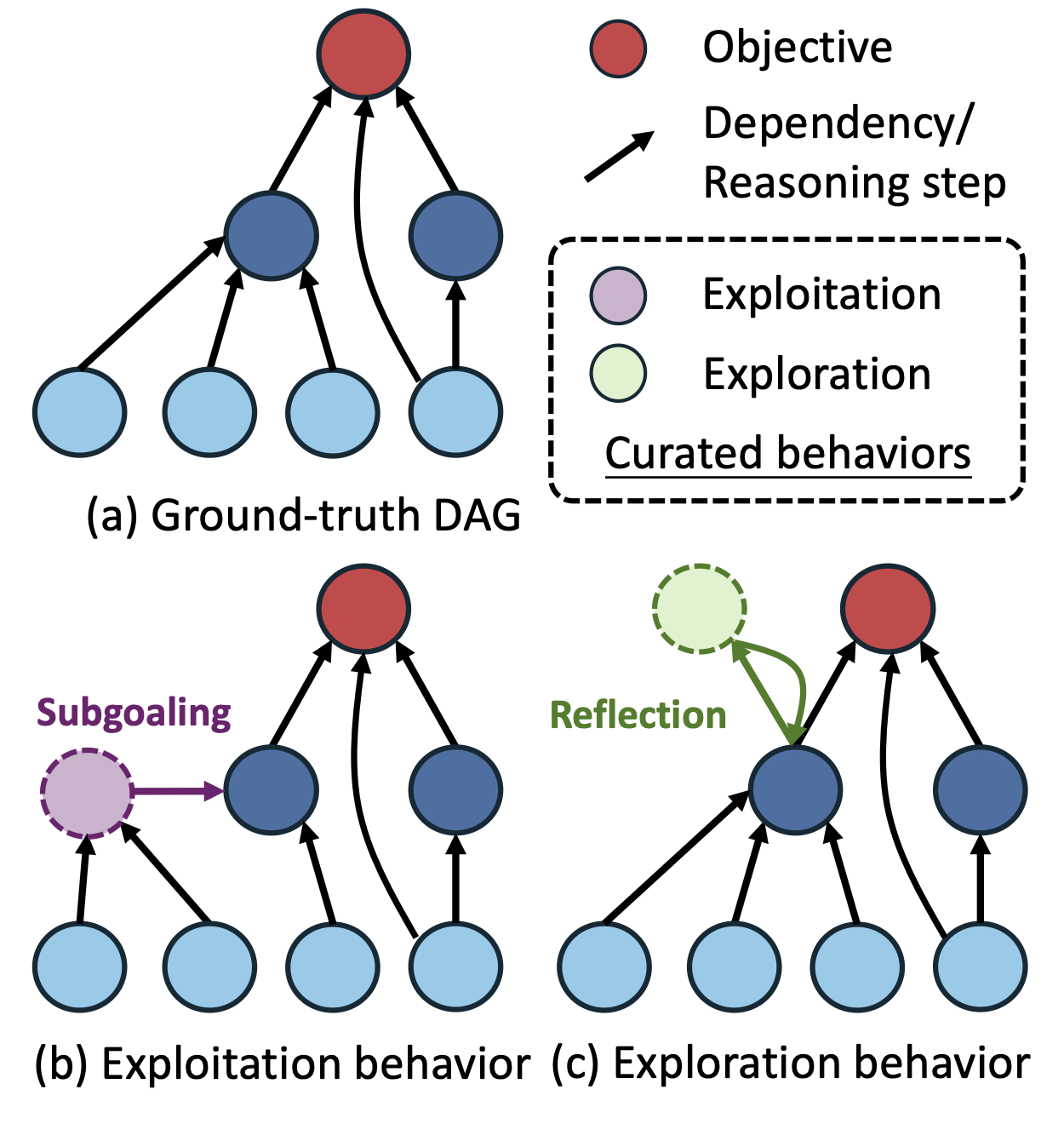
The exploration and exploitation
behaviors in DAG representation.

A simplified algorithmic overview
of BRIDGE.
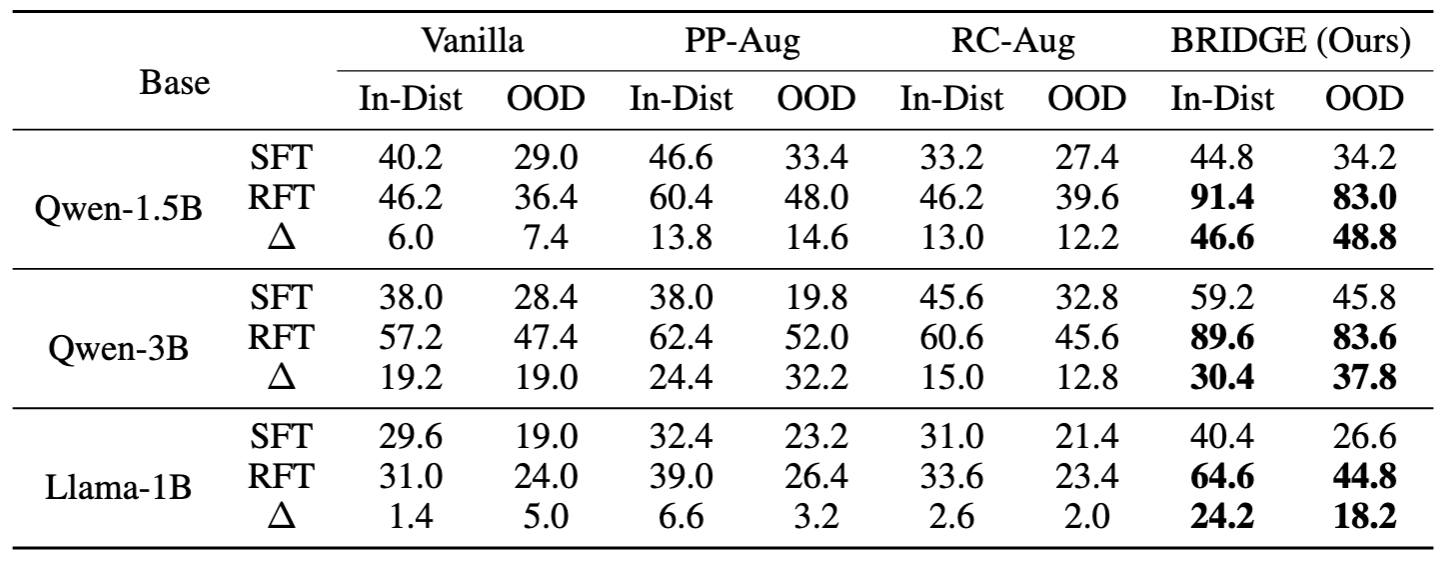
Table 1: The evaluation results (%) on the iGSM task. We compare SFT and RFT models on both in-distribution and out-of-distribution problem sets.
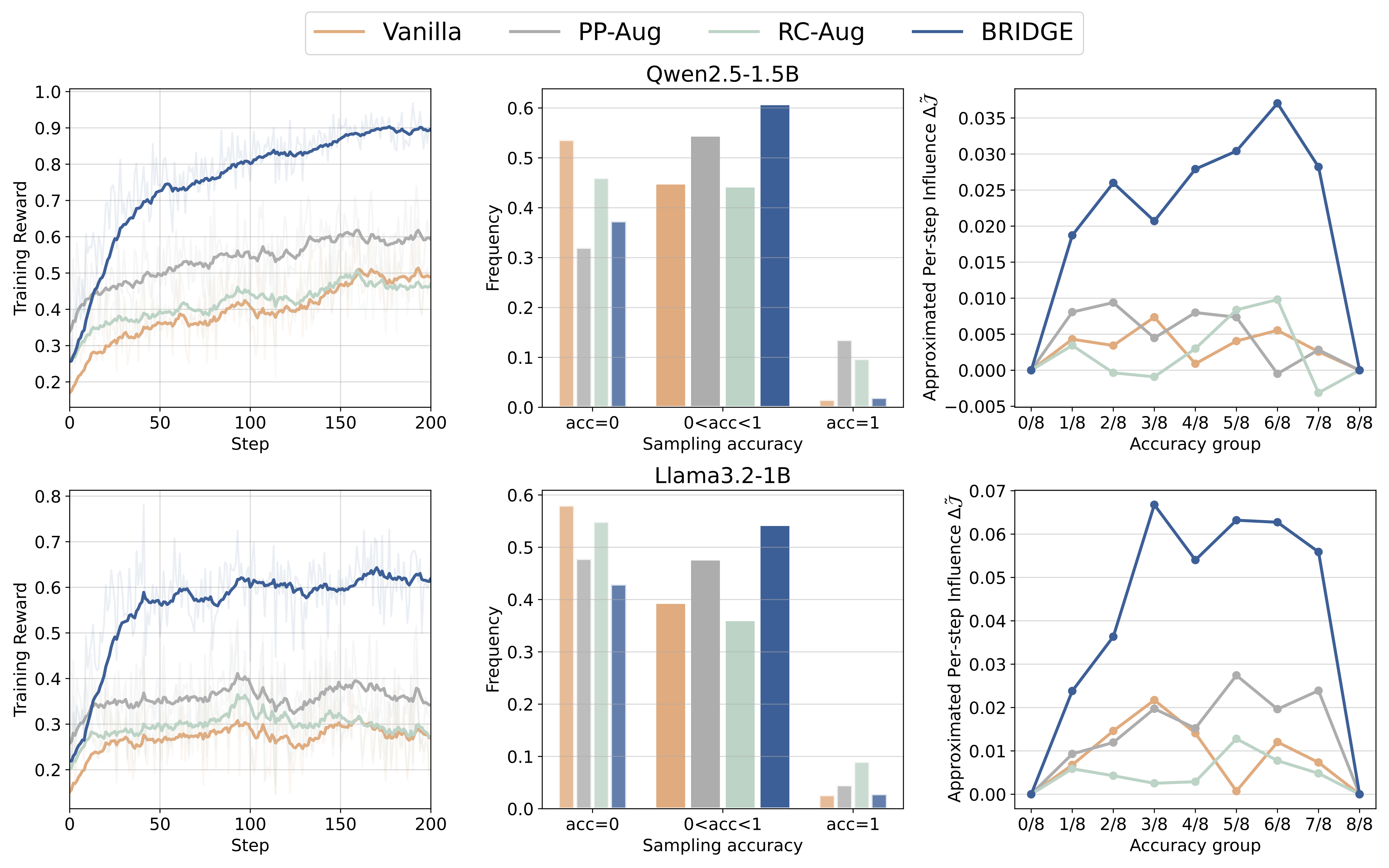
Fig. 1: Left Training reward curve. Middle: SFT model rollout accuracy distribution, note that only data with medium reward can contribute to the training. Right: Per-step influence visualization. We group the approximated per-step influence for samples with different accuracy.
We also release iGSM-reasoning, a synthetic infinite mathematical reasoning benchmark based on iGSM, which can serve as a testbed for evaluating LLM reinforcement finetuning with following advantages:
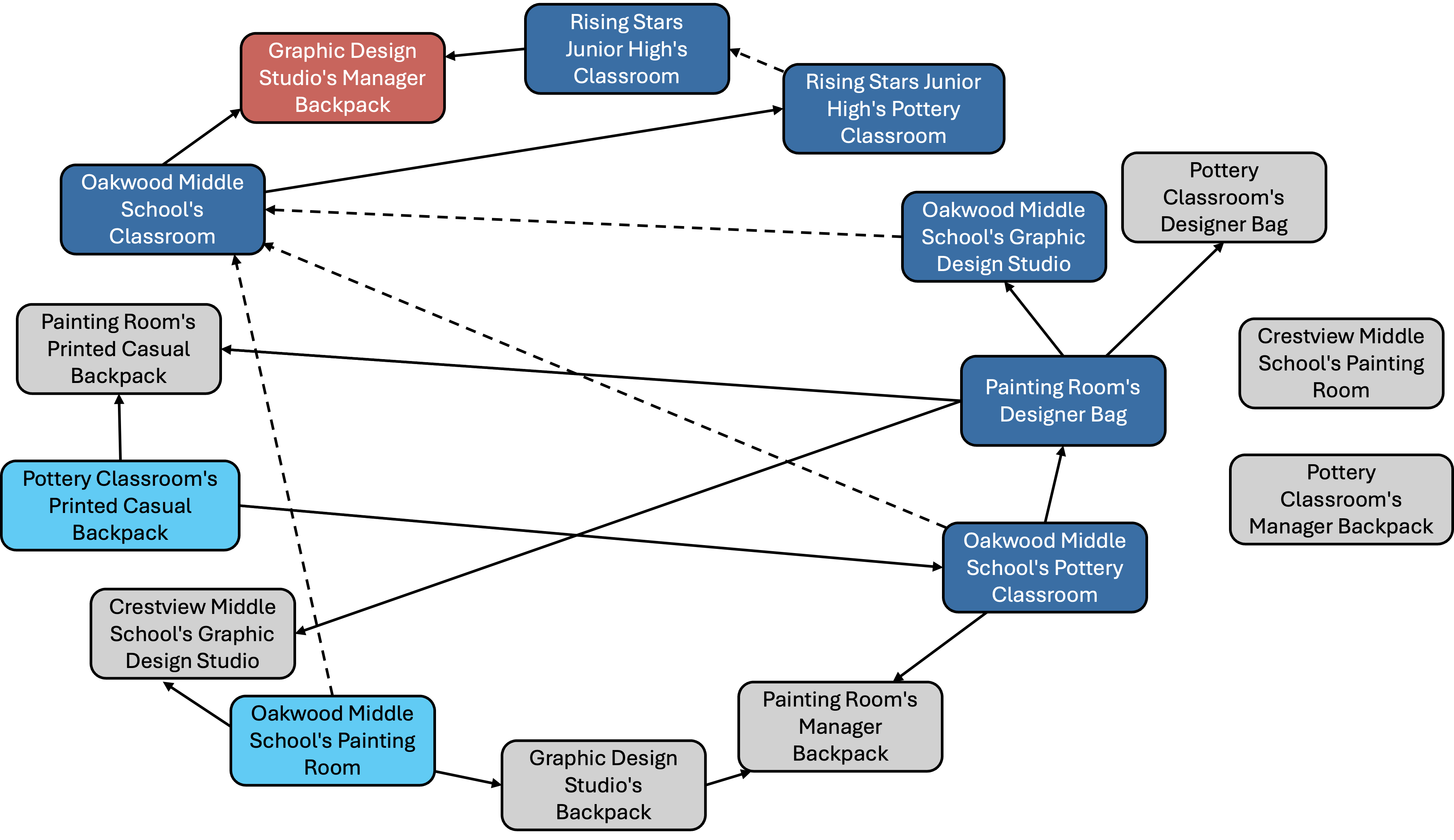
Fig. 2: DAG representation of an iGSM task. The red, light blue, dark blue, and gray rectangles mean the target, leaf, intermediate, and redundant nodes, respectively. The solid arrow indicates the explicit dependency which is explicitly given in query while the dash arrow means the implicit dependency which needs to be inferred by LLM.


Fig. 3: Top Question. Bottom left: Answer without exploratory and exploitative behaviors. Bottom Right: Answer with exploratory and exploitative behaviors.
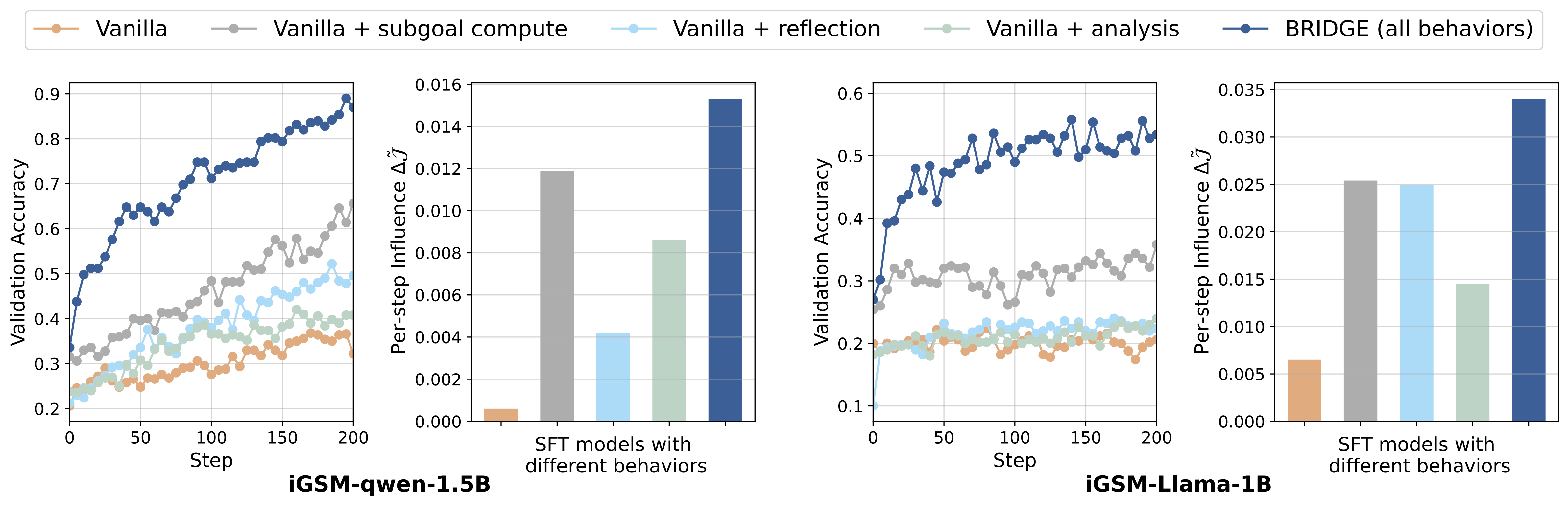
Fig. 4: The ablation of models with different behaviors in iGSM task. The model with full behaviors (i.e., both exploratory and exploitative) achieves the best performance.
@article{cen2025behavior,
title={Behavior Injection: Preparing Language Models for Reinforcement Learning},
author={Cen, Zhepeng and Yao, Yihang and Han, William and Liu, Zuxin and Zhao, Ding},
journal={arXiv preprint arXiv:2505.18917},
year={2025}
}